This paper is in fact a literature review on recent fuzz papers. I will first introduce some basic ideas of fuzzing. Second, I will review the state-of-the-art fuzzing research works. Finally, I will conclude several key questions researchers are facing when building a fuzzing framework. I will also analyze related papers to discuss their methodologies to answer these research questions. (I will continuously update this write-up while I read more papers about fuzzing).
Background
Fuzz is a kind of techniques for bug finding. To evaluate the security and reliability of the target program, fuzzers first generate abnormal inputs and monitor whether there will be a crash or not.
There are mainly four types of fuzzers: Blackbox fuzzing, mutation-based fuzzing, generation-based fuzzing, and coverage-guided fuzzing. Here we introduce the last three types which are commonly used [1].
Mutation-based fuzzing: Such fuzzer takes a well-formed input, randomly perturb (flipping bit, etc.). E.g., to obtain such input for a pdf reader, users may crawl a lot of pdf to build a corpus. Pros of this method is that little or no file format knowledge is required. Its limitation is also obvious, the quality of fuzzing is limited by initial corpus, and the inputs can be infinite.
Generation-based fuzzing: Test cases are generated from some description of the input format: RFC, documentation, etc. Anomalies are added to each possible spot in the inputs. The advantage of this method is its completeness. And it can also deal with complex dependencies (e.g, checksum)
The disadvantages are that writing generators are difficult, and performance depends on the quality of the generator.
- Coverage-guided fuzzing: This is a mutation of mutation-based fuzzing. It this method, target problem will be instrumented, and fuzzer will leverage the instrumentation to measure code coverage (Line coverage, Branch coverage, and Path coverage). It will search for mutants that result in coverage increase. It often uses genetic algorithms, i.e., try random mutations on test corpus and only add mutants to the corpus if coverage increases.
How researchers improved their fuzzers
In the beginning, I would like to draw a concept-level picture of fuzzing before I analyzed how and where researchers improved their tools.
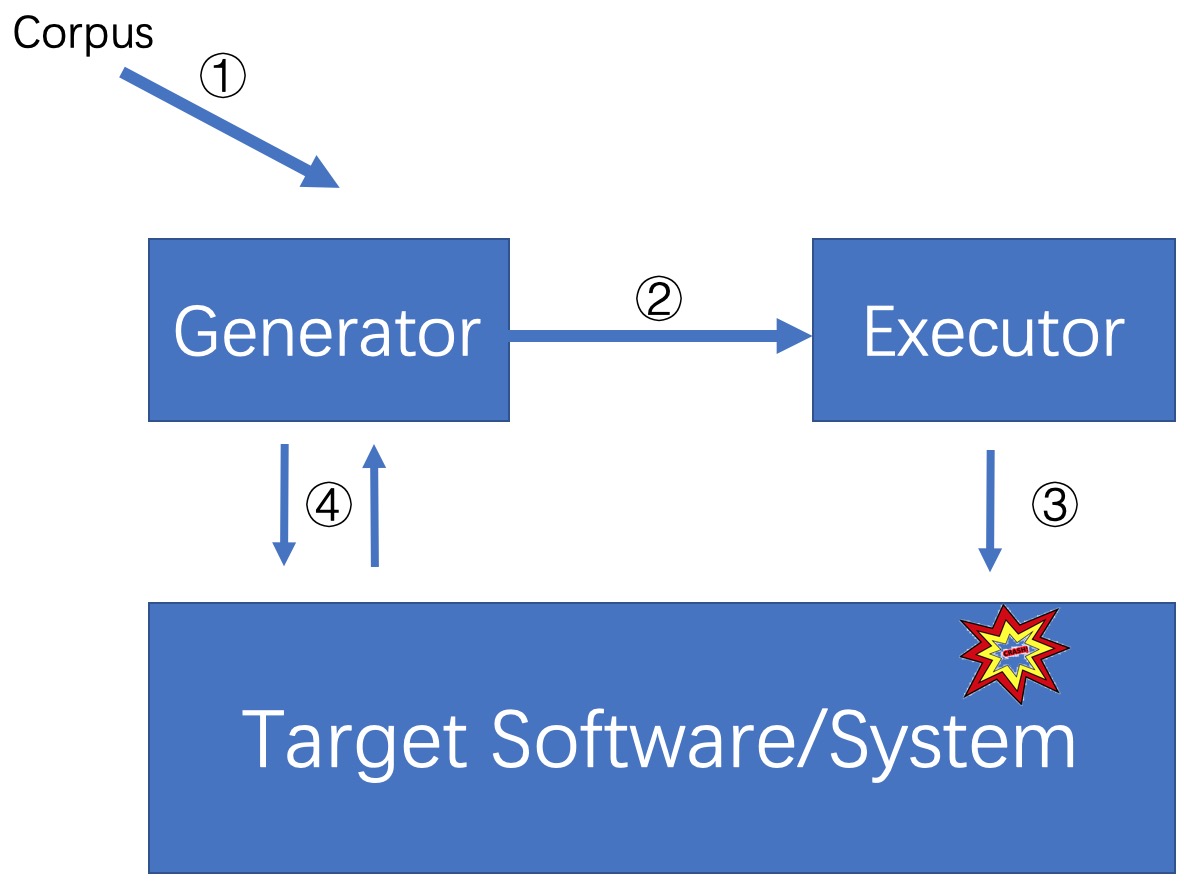
Moonshine[2] made contributions by improving OS fuzzers’ kernel code coverage. The problem they want to address is the behavior of some system calls usually depend on shared kernel state created by the previous system calls. As a result, fuzzers usually cannot reach deeper into the system call logic if they cannot have dependent kernel state correctly set. To address this problem, they proposed a static method to analyze real-world program traces in order to find the dependencies of system calls. If their contributions are discussed in the scope of this picture, the main improvement is actually made in the step (1). The dependency identifying process was called “Trace Distillation” in order to better sell their idea, however, the underlying method they employ to carry out the distillation is pretty straightforward, which is pointer analysis. Pointer analysis is a fundamental static program analysis. The goal of pointer analysis is to compute an approximation of the set of program objects that a pointer variable or expression can refer to. A interesting insight from this paper is that I found fuzz researches don’t afraid “false positive” as I imagine. I think this is because fuzzers are usually fast and automatic so they can remove these cases in the following steps within seconds. Instead, false negative is way more important in fuzzing context. As a result, I found fuzz researchers usually leverage a “overestimate” style to reduce False negative (increasing FP). Reflecting into the figure, they improved process 1.
Razzer[3] is the very technical paper which manipulate the execution of kernel to enlarge the possibilities of harmful data races. Razzer can be summarized as three phases. I. It performs a pointer analysis to pinpoint the potential data race instruction pairs. II. It leverages a random executor to find out a specific sequences of syscall which can reach previous instruction pair. III. It sends the sequences to the multi-thread executor and sets breakpoints before every two potential racy syscall pairs obtained from the phase II. Then it checks whether there is a race deterministically by executing the instruction of the two racy calls. An interesting insight from this paper is that one of its main contributions is to increase the success (reproduce) rate of harmful data races. By instrumenting the hypervisor, it is now able to deterministically trigger harmful data races. Reflecting into the figure, they improved process 3.
SlowFuzz[4] focuses on fuzzing algorithmic complexity vulnerabilities. Unlike previous works that used domain- and implementation-specific heuristics or rules, this paper proposed a domain-independent method to find the input that that trigger complexity vulnerabilities. From my perspective, finding such inputs seems to be a very challenging task because different algorithms have different sementics and thus different kinds of inputs in order to get slow down. To address this challenge, they proposed several input mutation strategies, which I think are the most interesting/important part of this paper. First, They concluded three situations that might lead to the increase of slow donw. (1) the choice of mutation operation (e.g., increase or decrease). (2) the chocice of mutation offset. (3) A combination of previous two. Second, they introudce probability for each stratygies. With probability a, operation or offsets that have best slow-down effects previously will be executed. With probability 1-a, operation or offsets will be randomly selected to be executed (a is 0.5 in this paper). This scheme is like a searching algorithm which not only greedly repeats previous good decisions but also consider other potential decisions based on probability. Reflecting into the figure, they improve the generator and process4.
Research Questions
The key problem for developing a fuzzing tool is how effectively can your newly proposed methodology help guide your fuzzer.
Interestingly, I found most papers ask similiar research questions.
- RQ1: Can you discover new vulnerabilities (effectiveness)
- RQ2: Can you improve code coverage?
- RQ3: How efficient is your tool(speed)?
- RQ4: How successful for the proposed method to address the key (sub)problem you focus on in this paper?
For papers that proposing a new fuzzing scheme/algorithm (most papers), RQ1 seems to be the most important question since it is the most convincing evidents about whether your method works or not.
For papers that claims that they make improvements by increasing code coverages, it is beyond dispute that they have to answer RQ2.
Experimentations
In this sections, I would like to talk about how they carried out experimentations to answer research questions above.
[1] http://www.cs.columbia.edu/~suman/secure_sw_devel/fuzzing.pdf
[2] Pailoor, Shankara, Andrew Aday, and Suman Jana. “MoonShine: Optimizing {OS} Fuzzer Seed Selection with Trace Distillation.” 27th USENIX Security Symposium. 2018.
[3] Jeong, Dae R., et al. “Razzer: Finding Kernel Race Bugs through Fuzzing.” Razzer: Finding Kernel Race Bugs through Fuzzing. IEEE S&P, 2018.
[4] Petsios, Theofilos, et al. “Slowfuzz: Automated domain-independent detection of algorithmic complexity vulnerabilities.” Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017.
[5] Petsios, Theofilos, et al. “Nezha: Efficient domain-independent differential testing.” 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017.